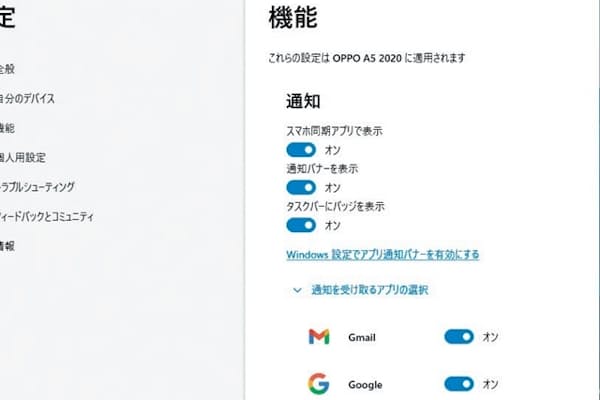
「迷惑メールフィルター」 仕組みを理解し正しく運用
完全撃退!迷惑メール(2)
ビジネススキル「迷惑メール」を撃退し、受信トレイをスッキリさせる各種の手法を3週にわたって解説する連載の2回目。今回は、フィッシング詐欺などにつながる危険なメールを自動で排除する「迷惑メールフィルター」をより深く理解して適切に運用する方法を解説する。現在、ほとんどのパソコンユーザーはすでに迷惑メールフィルターの恩恵にあずかっているはずだが、その仕組みや正しい運用方法は意外と知られていない。
◇ ◇ ◇
まずは、迷惑メールフィルターの基本を理解しよう(図1)。この機能は受信メールサーバーとメールアプリの2カ所に存在する。両方とも機能していることもあれば、どちらか一方だけが働いていることもある。2つのフィルターを機能させることにはそれなりの意味がある。迷惑メールの検出は簡単ではない。たまに迷惑メールが受信トレイに紛れ込むことがあるが、フィルターを二重にしておけば、サーバー側ですり抜けてもメールアプリ側で再判定できる。
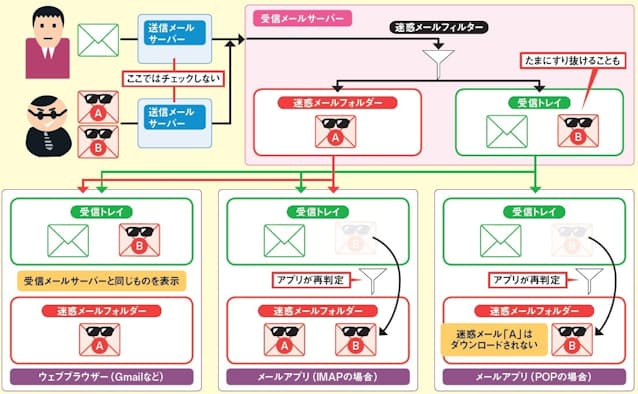
図1 迷惑メールフィルターは、受信メールサーバーとメールアプリ(Outlookなど)の2カ所にある。両方が稼働していることもあれば、どちらか一方だけが働いていることもある。メールの受信方式がPOPの場合、サーバー側で判別した迷惑メールはメールアプリには届かない。IMAPでは、サーバー側とアプリ側のそれぞれで判別された結果が合成される。なお、Gmailなどのウェブメール(ウェブブラウザー)ではサーバー側の迷惑メールフィルターだけが機能し、その結果がそのまま表示される
なお、サーバー側で迷惑メールと判定したメールの処理はサービスによって異なる。図1では専用フォルダーに隔離する例を示したが、件名に目印を付けて受信トレイに収めるサービスもある。また、メールアプリの受信方式が「POP」の場合、サーバー側で迷惑メールと判定されたメールはアプリに届かない。こうした運用上の注意点については、後ほど詳しく説明する。
次に、迷惑メールフィルターの仕組みを理解しよう。その判定技術は「ブロック」と「フィルター」に大別できる(図2)。ブロックは一般に、迷惑メールの発信元を手掛かりにメールを遮断すること。ユーザーが自分でブロック対象を指定することもあれば、メール事業者がブラックリストを基にブロックすることもある。一方のフィルターは、あらかじめ用意した基準にのっとって受信メールを1通ずつ判定する仕組みで、「ベイズ推定」「ニューラルネットワーク」「ランダムフォレスト」などの手法がある。実際には複数の方法を併用して迷惑メールを判別している。
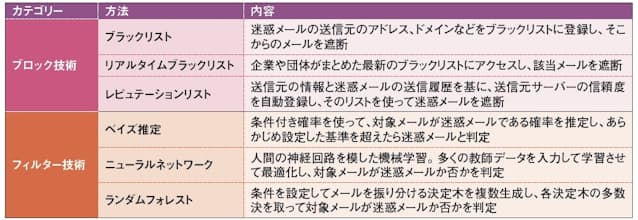
図2 迷惑メールフィルターの判別手法は、「ブロック」と「フィルター」に大別できる。ここには代表的なものを挙げたが、実際にはこれらを含む多くの手法から複数を組み合わせて運用している
フィルターではベイズ推定が中核的技術とされている。これは条件付き確率(ベイズの定理)を基にした推定で、「ベイジアンフィルター」とも呼ばれる。興味深い統計的な仕組みなので、図3にその考え方を示した。
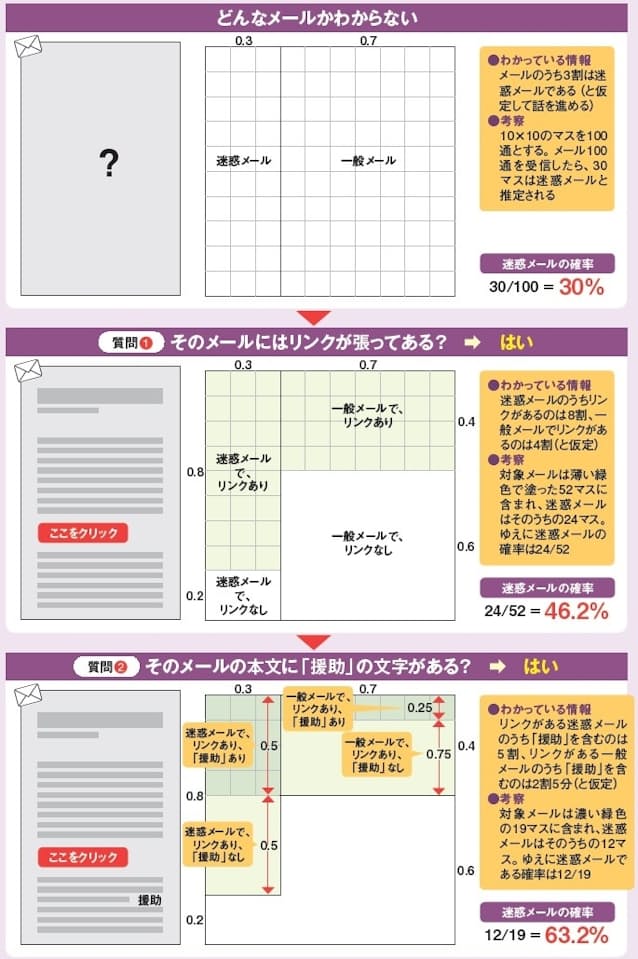
図3 ベイズ推定で迷惑メールを判別する例。考え方を理解しやすいように、架空の例で解説する。上段にある10×10=100個のマスはそれぞれメール1通を表すと考えよう。一般にメールのうち3割が迷惑メールという統計情報があるとする。すると、あるメールが届いたとき、それは100マスのどこかにあり、それが迷惑メールである確率は30/100、つまり30%と考えられる。中段では、そのメール本文にリンクがあるかを調べ、リンクがある場合について迷惑メールの確率を推定する。わかっている統計情報(仮定)は、迷惑メールのうちリンクがあるのは8割、一般メールでリンクがあるのは4割。すると、リンク付きメールは100マスのうち薄い緑色の52マスに含まれ、迷惑メールはそのうちの24マスを占める。つまり、迷惑メールの確率は24/52=46.2%となる。下段では、さらにそのメールに「援助」の文字がある場合における迷惑メールの確率を推定する。先ほどと同様の考え方に従って、図に示した「わかっている情報」を基に計算すると、迷惑メールの確率は12/19=63.2%と推定できる。つまり、もともとは30%だった迷惑メールの確率が、2つの条件を設定することで63.2%に上がった。実際にはさらに条件を追加して、あらかじめ設定してある迷惑メールの判定基準(たとえば95%)を超えたら、迷惑メールと判定する
ベイズ推定では「そのメールにリンクが張ってあるか」「本文に特定の文字(『援助』など)があるか」などの条件を基にして迷惑メールである確率を推定する。推定の際は「すべてのメールのうち迷惑メールの割合は〇割」「本文に『援助』があるのは一般のメールだと◯割だが迷惑メールだと□割」といった既知の統計情報を活用する。条件を増やすほど推定は正確になり、あらかじめ設定した確率を超えたものを迷惑メールと判定する。条件付き確率とは、ある条件下での確率という意味だ。